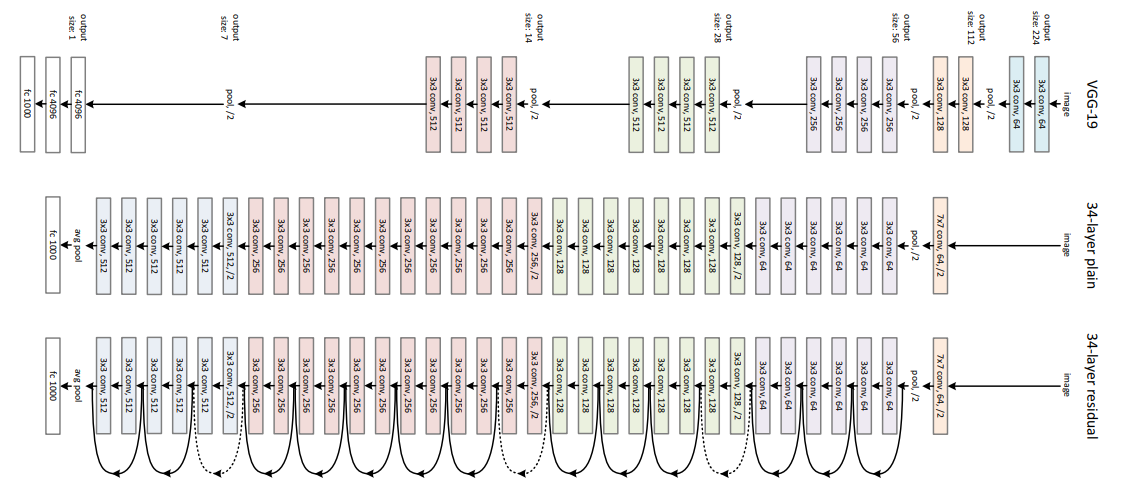
We present in this tutorial a starter guide to understand Information Retrieval in practice using Terrier platform with Cranfield dataset 🔗.
- Author : Dr. Oussama Ben Khiroun
- 1. Requirements
- 2. How to install Terrier v5.5 ?
- 3. What is Cranfield dataset ?
- 4. Indexing documents
- 5. Querying
- 6. What about stop words and stemming ?
- 7. Batch Retrieval
- 8. References
- 9. Credits
We will use the version 5.5 of Terrier (the last stable version while editing this tutorial). Using this version requires having version 11 or greater of Java. Java command should be also recognized in operating system paths.
Terrier will be used in this tutorial on Windows. However, all the steps are similar in Linux or Mac OS since Terrier is written in Java and it is portable.
You can test if Java is well configured by launching terminal on Windows (or Linux) and typing this command
> java -version
The current installed version of Java should be displayed
java version "17.0.1" 2021-10-19 LTS
Java(TM) SE Runtime Environment (build 17.0.1+12-LTS-39)
⚠️ if you have older version of Java than version 11, you should uinstall it and install a newer version. Find other details in Oracle web site
You just need to download the zip bin version for Windows (named terrier-project-5.5-bin.zip) from Terrier website and extract it for example under C:\
Rename Terrier folder with terrier-project-5.5
You should have subfolders like follows :
C:\terrier-project-5.5
├───bin
├───doc
├───etc
├───modules
├───share
├───src
└───varCranfield will be used as an example of test collection. It is small corpus of 1 400 scientific abstracts and 225 queries. It is considered among the first Information Retrieval initiatives to perform IR tasks in the 1960s.
Like any other test collection, Cranfield is composed of three parts :
- documents to be indexed
- a set of test queries (also known as topics)
- relevance judgment file (also known as Qrels)
⚠️ We suggest to experiment with Cranfield collection for learning purpose only. The collection (having 1 400 documents) is not so reliable when compared to Big Data IR collections used nowadays.
Terrier platform supports all TREC formatted collections. All Information Retrieval tasks from indexing, retrieving and evaluation can be performed easily on TREC collections. For this purpose, we transformed original Cranfield dataset to TREC format.
Required Cranfield files and detailed documentation can be found in this repository 🔗
We suggest to extract all downloaded files under a dedicated folder named cranfield under C:\
C:\cranfield
├───cran.all.1400.xml
├───cran.qry.xml
└───cranqrel.trec.txt- Using the command line, go to the Terrier
binfolder.
> cd C:\terrier-project-5.5\bin
- Setup Terrier for using Cranfield TREC test collection by using the
trec_setup.batscript
> trec_setup.bat C:\cranfield
This will result in the creation of a collection.spec file in the etc Terrier directory. This file contains a list of the document files contained in the specified Cranfield corpus directory.
We should modify the collection.spec file by removing files that we do not want to index (cran.qry.xml and cranqrel.trec.txt) as described in the trec_setup.bat command result
...
Updated collection.spec file. Please check that it contains all and only all
files to indexed, or create it manually
collection.spec:
----------------------------------------------
#add the files to index
C:\cranfield\cran.all.1400.xml
C:\cranfield\cran.qry.xml
C:\cranfield\cranqrel.trec.txt
----------------------------------------------
collection.spec file should contain only the 1400 documents file path needed to be indexed as follows :
C:\cranfield\cran.all.1400.xml
Now we are ready to begin the indexing of the collection. This is achieved using the batchindexing command of the terrier script, as follows:
> terrier batchindexing
...
14:25:23.611 [main] INFO o.terrier.indexing.CollectionFactory - Finished reading collection specification
14:25:23.625 [main] INFO o.t.i.MultiDocumentFileCollection - TRECCollection 0% processing C:\cranfield\cran.all.1400.xml
14:25:23.737 [main] INFO o.t.structures.indexing.Indexer - creating the data structures data_1
14:25:23.756 [main] INFO o.t.s.indexing.LexiconBuilder - LexiconBuilder active - flushing every 100000 documents, or when memory threshold hit
14:25:24.778 [main] WARN o.t.structures.indexing.Indexer - Adding an empty document to the index (471) - further warnings are suppressed
14:25:25.278 [main] INFO o.t.structures.indexing.Indexer - Collection #0 took 1 seconds to index (1400 documents)
14:25:25.281 [main] WARN o.t.structures.indexing.Indexer - Indexed 2 empty documents
14:25:25.349 [main] INFO o.t.s.indexing.BaseMetaIndexBuilder - ZstdMetaIndexBuilder meta achieved compression ratio 3.1755476 (> 1 is better)
14:25:25.418 [main] INFO o.t.s.indexing.LexiconBuilder - 1 lexicons to merge
14:25:25.424 [main] INFO o.t.s.indexing.LexiconBuilder - Optimising structure lexicon
14:25:25.428 [main] INFO o.t.s.i.FSOMapFileLexiconUtilities - Optimising lexicon with 6452 entries
14:25:25.696 [main] INFO o.t.structures.indexing.Indexer - Started building the inverted index...
14:25:25.722 [main] INFO o.t.s.i.c.InvertedIndexBuilder - BasicMemSizeLexiconScanner: lexicon scanning until approx 1.4 GiB of memory is consumed
14:25:25.733 [main] INFO o.t.s.i.c.InvertedIndexBuilder - Iteration 1 of 1 (estimated) iterations
14:25:25.982 [main] INFO o.t.s.indexing.LexiconBuilder - Optimising structure lexicon
14:25:25.983 [main] INFO o.t.s.i.FSOMapFileLexiconUtilities - Optimising lexicon with 6452 entries
14:25:26.006 [main] INFO o.t.structures.indexing.Indexer - Finished building the inverted index...
14:25:26.007 [main] INFO o.t.structures.indexing.Indexer - Time elapsed for inverted file: 0
Total time elaped: 2 seconds
...With Terrier’s default settings, the resulting index will be created in the var\index folder within the Terrier installation folder.
Once indexing completes, you can verify your index by obtaining its statistics, using the indexstats command of Terrier.
> terrier indexstats
Collection statistics:
number of indexed documents: 1400
size of vocabulary: 6452
number of tokens: 145321
number of postings: 89178
number of fields: 0
field names: []
blocks: falseThis displays the number of documents, number of tokens, number of terms, found in the created index.
The help of available Terrier commands can be displayed by typing terrier as follows
> terrier
Popular commands:
batchevaluate platform evaluate all run result files in the results directory
batchindexing platform allows a static collection of documents to be indexed
batchretrieval platform performs a batch retrieval "run" over a set of queries
help platform provides a list of available commands
interactive platform runs an interactive querying session on the commandline
All possible commands:
batchevaluate platform evaluate all run result files in the results directory
batchindexing platform allows a static collection of documents to be indexed
batchretrieval platform performs a batch retrieval "run" over a set of queries
help platform provides a list of available commands
help-aliases platform provides a list of all available commands and their aliases
http platform runs a simple JSP webserver, to serve results
indexstats platform display the statistics of an index
indexutil platform utilities for displaying the content of an index
interactive platform runs an interactive querying session on the commandline
inverted2direct platform makes a direct index from a disk index with only an inverted index
jforests platform runs the Jforests LambdaMART LTR implementation
pbatchretrieval platform performs a parallelised batch retrieval "run" over a set of queries
rest-singleindex platform starts a HTTP REST server to serve a single index
showdocument platform displays the contents of a document
structuremerger platform merges 2 disk indices
trec_eval platform runs the NIST standard trec_eval tool
We can use the terrier interactive command to query the index for results.
> terrier interactive
14:33:44.639 [main] INFO o.t.s.BaseCompressingMetaIndex - Structure meta reading lookup file into memory
14:33:44.646 [main] INFO o.t.s.BaseCompressingMetaIndex - Structure meta loading data file into memory
terrier query>Once the query prompt is displayed, you can enter some queries for test. For example, let’s test with study of temperature.
terrier query> study of temperature
14:38:20.625 [main] INFO org.terrier.querying.LocalManager - Starting to execute query interactive4 - study of temperature
...
14:38:20.652 [main] INFO org.terrier.querying.LocalManager - Finished executing query interactive4 in 27ms - 462 results retrieved
Displaying 1-462 results
0 549 5.794936876261285
1 865 5.491204121605947
2 29 5.282352789647487
3 90 5.080041785645402
4 1269 5.04726774599607
5 1314 4.77766074135166
6 912 4.72547801712598
7 836 4.719158743858431
8 407 4.4903944412638035
9 585 4.449015692155355
10 293 4.294205418924092
11 967 4.231562902060937
12 550 4.231495541986411
...
In responding to the query study of temperature, Terrier estimated document having id n° 549 to be most relevant, scoring 5.79.
N° 549 was recorded from the <docno> tag of the corresponding document.
To quit the querying prompt, just enter “exit” as query term.
Terrier supports a specific query language to exclude and weight terms. Find details in query language documentation.
Terrier use a term pipeline specified in terrier.properties under etc folder.
The default term pipeline is configured to use Stopwords and PorterStemmer as follows in terrier.properties (line 29)
...
#the processing stages a term goes through
termpipelines=Stopwords,PorterStemmer
...On the one hand, the list of English stop words that will be ignored in retrieval task is contained in stopword-list.txt file under share folder.
Some words listed in this file : and, then, of, are, by, etc.
When using other language, consider changing this list with an appropriate one. Many stopwords lists supporting other languages could be found freely from Internet.
On the other hand, stemming helps to truncate terms by removing prefixes and suffixes. This is applied in both indexing and retrieval steps. PorterStemmer is an example of stemming algorithms (SnowballStemmer is another commonly used one).
In conclusion, if we focus on the used query study of temperature in previous section, it will have exactly the same result of studying temperature. In fact, of is considered as a stop word and studying will be stemmed by removing the ING suffix to have the same stem of study.
💡 All modern information retrieval systems implement such strategy.
First of all, we have to do some configuration. Much of Terrier’s functionality is controlled by properties.
You can pre-set these in the etc\terrier.properties file, or specify each on the command-line.
Some commonly used properties have short options to set these on the command-line (use
terrier help <command>to see these).
To perform retrieval and evaluate the results of a batch of queries, we need to know:
-
The location of the queries (also known as topic files) – specified using the
trec.topicsproperty, or the short-tcommand-line option tobatchretrieval. -
The weighting model (e.g. TF_IDF) to use – specified using
trec.modelproperty or the-woption to batchretrieval. The default weighting model for Terrier is DPH. -
The corresponding relevance assessments file (or qrels) for the topics – specified by
trec.qrelsor-qoption tobatchevaluate.
In order to simplify commands options in the following steps, we will add two configurations of queries (topics) and relevance assessments (qrels) that will not be changed in etc\terrier.properties file as follows
(Lines to be added in etc\terrier.properties file)
trec.topics=C:\\cranfield\\cran.qry.xml
trec.qrels=C:\\cranfield\\cranqrel.trec.txt
Pay attention to put double
\\in paths to despecialize the backslash character.
The batchretrieval command instructs Terrier to do a batch retrieval run, i.e. retrieving the documents estimated to be the most relevant for each query in the topics file. This trec.topics property is already added in terrier.properties file by referring the end of the previous section.
Run batch retrieval (it would take some seconds to complete):
> terrier batchretrieval
...
15:30:34.669 [main] INFO o.t.matching.PostingListManager - Query 365 with 10 terms has 10 posting lists
15:30:34.676 [main] INFO org.terrier.querying.LocalManager - running process PostFilterProcess
15:30:34.677 [main] INFO org.terrier.querying.LocalManager - running process SimpleDecorateProcess
15:30:34.677 [main] INFO org.terrier.querying.LocalManager - Finished executing query 365 in 11ms - 996 results retrieved
15:30:34.678 [main] INFO o.t.a.batchquerying.TRECQuerying - Time to process query 365: 0.012
15:30:34.708 [main] INFO o.t.a.batchquerying.TRECQuerying - Settings of Terrier written to C:\terrier-project-5.5\var\results/DPH_0.res.settings
15:30:34.717 [main] INFO o.t.a.batchquerying.TRECQuerying - Finished topics, executed 225 queries in 5.37 seconds, results written to C:\terrier-project-5.5\var\results/DPH_0.res
This will result in a .res file in the var\results directory called DPH_0.res. We call each .res file a run, and contains Terrier’s answers to each of the 225 queries.
Sample of .res file :
| TOPIC | EXTRA COLUMN | DOCNO | RANK | RELEVANCE SCORE | MODEL |
|---|---|---|---|---|---|
| 1 | Q0 | 51 | 0 | 19.800718637881634 | DPH |
| 1 | Q0 | 486 | 1 | 18.67288171863144 | DPH |
| 1 | Q0 | 12 | 2 | 16.191100749192266 | DPH |
| 1 | Q0 | 184 | 3 | 15.211695868416541 | DPH |
| 1 | Q0 | 878 | 4 | 14.29537290863017 | DPH |
| 1 | Q0 | 665 | 5 | 12.13011101490366 | DPH |
| 1 | Q0 | 746 | 6 | 11.926074045474698 | DPH |
| 1 | Q0 | 573 | 7 | 11.461285434379176 | DPH |
| 1 | Q0 | 141 | 8 | 11.264373653439682 | DPH |
| … | … | … | … | … | … |
You can also configure more options on the command-line, including arbitrary properties using the -D option to any Terrier command. So the following two commands are equivalent:
> terrier batchretrieval -w BM25
> terrier batchretrieval -Dtrec.model=BM25We have instructed Terrier to perform retrieval using the BM25 weighting model.
BM25 is a classical Okapi model firstly defined by Stephen Robertson, instead of the default DPH, which is a Divergence From Randomness weighting model.
After running batchretrieval for the second weighting model, we will have a second .res file in the var\results directory called BM25_1.res.
All runs names are incremented using a counter system (in querycounter file under var\results). We can run as many runs before performing evaluation by changing weighting models and tuning parameters of each one.
Other parameters of weighting models can be specified with options (see further details about configuring retrieval in Terrier documentation)
Now we will evaluate the obtained results by using the batchevaluate command :
> terrier batchevaluate
16:10:10.606 [main] INFO o.t.evaluation.TrecEvalEvaluation - Evaluating result file: C:\terrier-project-5.5\var\results/BM25_1.res
Average Precision: 0.0148
16:10:11.359 [main] INFO o.t.evaluation.TrecEvalEvaluation - Evaluating result file: C:\terrier-project-5.5\var\results/DPH_0.res
Average Precision: 0.0132
Terrier will look at the var\results directory, evaluate each .res file and save the output in a .eval file named exactly the same as the corresponding .res file.
C:\terrier-project-5.5\var\results
├───BM25_1.eval
├───BM25_1.res
├───BM25_1.res.settings
├───DPH_0.eval
├───DPH_0.res
├───DPH_0.res.settings
└───querycounterNow we can look at all the Mean Average Precision (MAP) values of the runs by inspecting the .eval files in var\results:
runid all DPH
num_q all 152
num_ret all 129408
num_rel all 1074
num_rel_ret all 699
map all 0.0132
gm_map all 0.0024
Rprec all 0.0132
bpref all 0.4007
recip_rank all 0.0336
iprec_at_recall_0.00 all 0.0382
iprec_at_recall_0.10 all 0.0351
iprec_at_recall_0.20 all 0.0235
iprec_at_recall_0.30 all 0.0164
iprec_at_recall_0.40 all 0.0149
iprec_at_recall_0.50 all 0.0130
iprec_at_recall_0.60 all 0.0100
iprec_at_recall_0.70 all 0.0071
iprec_at_recall_0.80 all 0.0056
iprec_at_recall_0.90 all 0.0039
iprec_at_recall_1.00 all 0.0028
P_5 all 0.0132
P_10 all 0.0125
P_15 all 0.0118
P_20 all 0.0125
P_30 all 0.0112
P_100 all 0.0080
P_200 all 0.0069
P_500 all 0.0056
P_1000 all 0.0046
The above displayed evaluation measures are averaged over a batch of queries. Results seem to be not satisfying having a very low Mean Average Precision = 0.0132. Thus we should investigate more these results by running evaluation per query apart.
We can obtain per-query results by using option -p in the command line:
> terrier batchevaluate -p
Old
.evalshould be deleted before running -p option.
The resulting output saved in the corresponding .eval files will contain further results per query, with the middle column indicating the query id.
Let’s consider the query n°1 (see cran.qry.xml)
<top>
<num> 1</num>
<title>
what similarity laws must be obeyed when constructing aeroelastic models of heated high speed aircraft .
</title>
</top>This is a sample of query n°1 in the generated .eval per query file
num_ret 1 825
num_rel 1 28
num_rel_ret 1 25
map 1 0.2334
Rprec 1 0.3214
bpref 1 0.0357
recip_rank 1 1.0000
iprec_at_recall_0.00 1 1.0000
iprec_at_recall_0.10 1 0.7500
iprec_at_recall_0.20 1 0.3684
iprec_at_recall_0.30 1 0.3214
iprec_at_recall_0.40 1 0.2727
iprec_at_recall_0.50 1 0.1562
iprec_at_recall_0.60 1 0.0960
iprec_at_recall_0.70 1 0.0781
iprec_at_recall_0.80 1 0.0413
iprec_at_recall_0.90 1 0.0000
iprec_at_recall_1.00 1 0.0000
P_5 1 0.6000
P_10 1 0.3000
P_15 1 0.3333
P_20 1 0.3500
P_30 1 0.3000
P_100 1 0.1500
P_200 1 0.0850
P_500 1 0.0420
P_1000 1 0.0250
We can see that this query returned 25 relevant documents all over 28 relevant documents judged in qrels file.
The Mean Average Precision (MAP) of this query is 0.2334. This query example performs well for different precision/recall points (see iprec_at_recall_ data that can be used to trace Precision-Recall curve).
However, some queries have no relevant returned documents (in some cases relevant documents are returned in last ranks) which leads to a low overall MAP value.
If you find this tutorial useful, consider sharing/citing and starring it on Github.
- Author : Dr. Oussama Ben Khiroun
 https://github.com/oussbenk/information-retrieval-tutorial-terrier-cranfield
https://github.com/oussbenk/information-retrieval-tutorial-terrier-cranfield